これまで色々なデータベース操作を学んできましたが、
バックアップリカバリは障害が発生したときに非常に重要な項目です。
ではデータベースに関係する障害とはどのようなものがあるでしょうか。
データベース障害
データベースの障害は様々あります。大きくな分類として以下の項目があります。
・ユーザ障害
・ネットワーク障害
・サーバ障害
・メディア障害
ユーザ障害
ユーザ障害はユーザによるオペレーションミスにより発生する障害です。
例えばユーザが誤ってデータを削除してしまったなどがあります。
復旧方法は、フラッシュバック機能やバックアップリカバリなどで対処します。
ネットワーク障害
ネットワーク障害はネットワークが問題でデータベースに接続できなくなってしまうなどの障害です。物理的にNICが壊れてしまったなどがありますが、この場合、DBAとしての作業は特にありません。
サーバ障害
サーバ障害はデータベースサーバがハードの異常を検知し、OSが再起動もしくは停止してしまい、DBが正常に停止できず異常終了してしまう障害です。
データベースはデータベースバッファキャッシュ上の更新されたデータブロックがデータファイルに書き込まれずに消えてしまいます。この状況をインスタンス障害といいます。
インスタンス障害はDBを起動すれば、自動的にメモリ上で消失してしまったデータを自動的に復旧します。これをインスタンスリカバリと言います
メディア障害
物理的にデータファイルや制御ファイルなどが破損してしまいDBが起動できなくなる障害です。この場合、バックアップを使用した復旧が必要です。
上記の様に障害といっても様々な障害があります。まずは障害発生時、どのような障害が発生しているかを切り分け、各障害に対して適切な対応をすることでDBの停止時間を最小限にすることができます。
インスタンス障害
インスタンス障害はDBを再起動することで自動的に復旧します。
ただしDBAはどのように復旧作業を行っているかを理解しておく必要があります。
インスタンス障害とはデータベースバッファキャッシュ上で変更されたデータブロックが、データファイルに書き込まれずに、強制停止されてしまった場合に発生します。
この場合はデータベースを起動すると、Oracleはデータベースに不整合が発生していることを認識し、インスタンスリカバリを実施します。
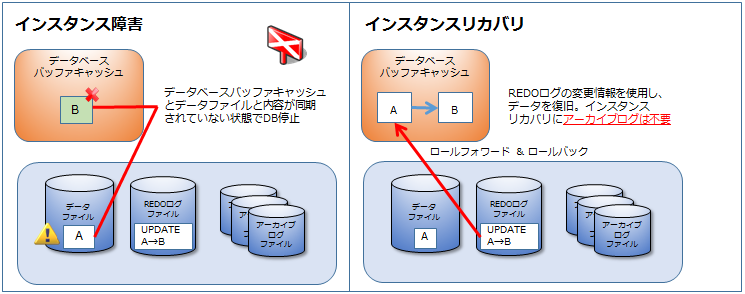
インスタンスリカバリは次の流れで実施されます。
1. DB起動、MOUNT後、データファイルの整合性チェック
2. ロールフォワードの実施
3. ロールバックの実施
REDOログファイルの変更情報を適用することをロールフォワードと言います。
またインスタンスリカバリで使用する変更情報はREDOログのみであり、アーカイブログは不要です。ロールフォワード実施後、COMMITしていないトランザクションを取消する為、ロールバックを実施します。
インスタンスリカバリはDBを再起動すれば自動的に実施されるため、DBAが復旧作業を行う必要はありませんが、リカバリ時間を把握し、リカバリにかかる時間を想定しておくことは重要です。
インスタンスリカバリにかかる時間は「REDOログファイルの変更情報を適用する量」に比例します。 ではこのREDOログの量はどのように調整するのでしょうか。
インスタンスリカバリの目標復旧時間
インスタンスリカバリは変更情報を適用するロールフォワードが主な内容です。
適用する変更情報が多ければ、リカバリに時間を要します。 適用する変更情報を少なくすればインスタンスリカバリにかかる時間が少なくなります。
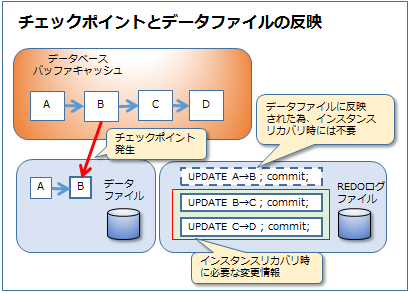
変更情報が不要になるのはその更新がデータファイルに反映された時です。反映されるタイミングはチェックポイントというイベントでしたね。
チェックポイントが発行されると、データベースバッファキャッシュ上の変更された
データブロックがデータファイルに書き込まれます。そのタイミングでそれ時点のREDOログの変更情報は不要となります。
つまりインスタンスリカバリの時間を短縮したい場合は、チェックポイントの頻度を上げることで調整します。インスタンスのリカバリ時間を制御するには、FAST_START_MTTR_TARGETパラメータを設定します。
FAST_START_MTTR_TARGETパラメータはインスタンス障害のリカバリ目標時間を設定します。このパラメータを設定すると、指定した時間にインスタンスリカバリが完了するようにチェックポイントの頻度を自動的に調整します。
しかしFAST_START_MTTR_TARGETを短くしすぎると、チェックポイントの発行が多くなるため、パフォーマンスが低下しますのでご注意ください。
[パラメータ] FAST_START_MTTR_TARGET
インスタンスリカバリにかかる目標時間(秒)
インスタンスリカバリにかかる目標時間(秒)
インスタンスリカバリは自動的に復旧しますが、インスタンスリカバリにかかる時間を決めておきたい場合は、このパラメータを設定します。
メディア障害
メディア障害はデータファイルや制御ファイルなど物理的にファイルが破損する
障害です。
まずデータベースとして以下のファイルがあります。
・データファイル(クリティカル表領域、非クリティカル表領域)
・制御ファイル
・REDOログファイル
・アーカイブログファイル
・SPFILE
上記ファイルが破損した場合、どのような動作となるのか確認していきます。
データファイル障害
クリティカルデータファイルと非クリティカルデータファイルがあり、破損した表領域によって障害時の動作が異なります。
クリティカルデータファイルが破損するとDBは停止します。
非クリティカルデータファイルの障害は停止しません。

Oracle Database 11g R11.2.0.1以前のバージョンでは上記動作となりますが、
Oracle Database 11g R11.2.0.1以降のバージョンでは動作が変わりクリティカル表領域でも非クリティカル表領域でも障害発生時にデータベースが停止します。
データファイルの障害が発生した場合はバックアップを使用したメディアリカバリが必要になります。
| クリティカル データファイル |
SYSTEM,UNDO表領域 |
|---|---|
| 非クリティカル データファイル |
SYSTEM,UNDO表領域以外の表領域 |
制御ファイル障害
制御ファイルは冗長化された制御ファイルの1つでも破損してしまった場合、データベースは停止します。 制御ファイルは障害に備え、ファイルの冗長化が可能です。
この冗長化は障害発生時、復旧時間が少なる目的での冗長化となります。
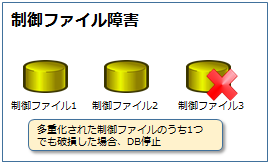
障害が発生した場合、正常な制御ファイルを破損したファイルにコピーするだけです。
制御ファイルすべてが破損してしまうと、バックアップから復旧が必要です。
こうなると復旧作業は長時間となってしまいますね。その為、制御ファイルは障害に備え冗長化する必要があります。
REDOログファイル障害
REDOログファイルは冗長化された1つのメンバーが破損してもデータベースは停止しません。 グループ内のすべてのメンバーが破損した場合、データベースは停止します。

グループ内で冗長化されたファイルをメンバーと呼びます。
上記の例のように、2つのメンバーを持つREDOロググループ1があるとして、
そのうちの1つのメンバーが破損した場合、DBは停止しませんが、グループ内のすべてのメンバーが破損した場合はDBは停止します。
1つのメンバーが破損した場合の復旧方法は制御ファイルと同じで破損していないファイルを破損したファイルにコピーするだけですが、全損の場合はバックアップからの復旧となります。
制御ファイルの多重化
メディア障害時のDB停止時間を出来るだけ、縮小する為、多重化可能な制御ファイルは多重化することを推奨します。
制御ファイルの多重化は以下の方法で行います。
1. control_filesパラメータの変更
2. DB停止
3. OS上で制御ファイルをコピー
4. DB起動
2. DB停止
3. OS上で制御ファイルをコピー
4. DB起動
では実行例をみていきましょう。
1. control_filesパラメータの変更
ONTROL_FILESパラメータを変更し、追加する制御ファイル名を追記します。
SQL> show parameter control_files
NAME TYPE VALUE
------------------------- ----------- ------------------------------
control_files string /u01/app/oracle/oradata/orcl/c
ontrol01.ctl, /u01/app/oracle/
oradata/orcl/control02.ctl
制御ファイルはcontrol01.ctl,control02.ctlという2つのファイルで構成されています。OSファイル上も以下の様に作成されています。
SQL> !ls -l /home/oracle/12101/oradata/orcl/*.ctl
-rw-r----- 1 oracle oinstall 17973248 XX XX XX:XX 2017 control01.ctl -rw-r----- 1 oracle oinstall 17973248 XX XX XX:XX 2017 control02.ctl
では多重化のために3つ目の制御ファイルを作成する為、パラメータを変更します。
SQL> ALTER SYSTEM SET control_files = 2 '/u01/app/oracle/oradata/orcl/control01.ctl', 3 '/u01/app/oracle/oradata/orcl/control02.ctl', 4 '/u01/app/oracle/oradata/orcl/control03.ctl' 5 SCOPE=spfile; System altered. SQL> show parameter control_files NAME TYPE VALUE ------------------------- ----------- ------------------------------ control_files string /u01/app/oracle/oradata/orcl/c ontrol01.ctl, /u01/app/oracle/ oradata/orcl/control02.ctl
追加でcontrol03.ctlというファイルをパラメータに指定しました。
SCOPE=SPFILEですので、このパラメータは再起動後、設定が反映されます。
control_filesは静的パラメータであり、SCOPE=BOTHは使用できません。
2. DB停止
次にDBを停止します。
SQL> SHUTDOWN IMMEDIATE
Database closed.
Database dismounted.
ORACLE instance shut down.
3. OS上で制御ファイルをコピー
制御ファイルをコピーしていきます。制御ファイルのコピーは
必ずDBを停止した状態で実施します。
$ cd /u01/app/oracle/oradata/orcl $ ls *.ctl control01.ctl control02.ctl $ cp -p control02.ctl control03.ctl $ ls *.ctl control01.ctl control02.ctl control03.ctl
既存の制御ファイルをコピーしcontrol03.ctlのファイルを作成します。
4. DB起動
では最後にDBを起動していきましょう。
$ sqlplus / as sysdba SQL*Plus: Release 12.1.0.1.0 Production on XX XX XX XX:XX:XX 2017 Copyright (c) 1982, 2013, Oracle. All rights reserved. Connected to an idle instance. SQL> startup ORACLE instance started. Total System Global Area 801701888 bytes Fixed Size 2293496 bytes Variable Size 327155976 bytes Database Buffers 465567744 bytes Redo Buffers 6684672 bytes Database mounted. Database opened. SQL> SELECT status FROM v$instance; STATUS ------------ OPEN SQL> show parameter control_files NAME TYPE VALUE ------------------------- ----------- ------------------------------ control_files string /u01/app/oracle/oradata/orcl/c ontrol01.ctl, /u01/app/oracle/ oradata/orcl/control02.ctl, /u 01/app/oracle/oradata/orcl/con trol03.ctl
control_filesパラメータの設定が反映され、制御ファイル(control03.ctl)ファイルが
新しく追加されました。ここでDB起動に失敗した場合は以下の原因が考えられます。
・DB起動中に制御ファイルをコピーしてした
・control_filesパラメータで指定したファイル名と異なるファイル名でコピーした
以上が制御ファイルの多重化方法です。
REDOログファイルの多重化
次はREDOログの多重化方法です。
まずはREDOログファイルの情報を確認してみましょう。
REDOロググループの情報はV$LOGというデータディクショナリで確認ができます。
SQL> SELECT group#,bytes,members,status FROM v$log;
GROUP# BYTES MEMBERS STATUS
---------- ---------- ---------- ----------------
1 52428800 1 INACTIVE
2 52428800 1 INACTIVE
3 52428800 1 CURRENT
現在REDOログはMEMBERが1の50MBの3つのグループで構成されており
各グループ多重化されていない状態です。
またSTATUSがCURRENTは現在書き込みを行っているREDOロググループです。
| CURRENT | 現在アクティブのロググループ |
|---|---|
| ACTIVE | 非アクティブだがインスタンスリカバリで 必要な変更情報が含まれるロググループ |
| INACTIVE | 非アクティブのロググループ |
| UNUSED | 1度も使用していないロググループ。 作成時はこの状態となる。 |
では次にREDOログのメンバ情報を確認しましょう。
V$LOGFILEというデータディクショナリで確認ができます。
SQL> SELECT group#,type,member FROM V$logfile;
GROUP# TYPE MEMBER
---------- ------- --------------------------------------------------
3 ONLINE /u01/app/oracle/oradata/orcl/redo03.log
2 ONLINE /u01/app/oracle/oradata/orcl/redo02.log
1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log
それでは各ロググループの多重化を行っていきます。
SQL> ALTER DATABASE ADD LOGFILE MEMBER 2 '/u01/app/oracle/oradata/orcl/redo01_01.log' TO GROUP 1; Database altered. SQL> SELECT group#,type,member FROM V$logfile; GROUP# TYPE MEMBER ---------- ------- -------------------------------------------------- 3 ONLINE /u01/app/oracle/oradata/orcl/redo03.log 2 ONLINE /u01/app/oracle/oradata/orcl/redo02.log 1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log 1 ONLINE /u01/app/oracle/oradata/orcl/redo01_01.log SQL> SELECT group#,bytes,members,status FROM v$log; GROUP# BYTES MEMBERS STATUS ---------- ---------- ---------- ---------------- 1 52428800 2 INACTIVE 2 52428800 1 INACTIVE 3 52428800 1 CURRENT
ロググループ1にメンバーを追加することができました。ロググループはSTATUSがINACTIVEの状態で追加しましたが、ACTIVEの場合も同様に追加可能です。
制御ファイル、REDOログファイルの多重化方法を確認しました。
多重化可能なファイルは多重化していきましょう。ただし多重化しすぎても
ファイル障害の確率が高くなるので注意しましょう。
制御ファイル破損時の復旧(一部)
では1つの制御ファイルを削除し、動作を確認していきましょう。
$ ls *.ctl control01.ctl control02.ctl control03.ctl $ rm control03.ctl $ ls *.ctl control01.ctl control02.ctl
control03.ctlの制御ファイルを消したのでDBを停止します。
SQL> shutdown immediate ORA-00210: cannot open the specified control file ORA-00202: control file: '/u01/app/oracle/oradata/orcl/control03.ctl' ORA-27041: unable to open file Linux-x86_64 Error: 2: No such file or directory Additional information: 3 SQL> shutdown abort ORACLE instance shut down.
IMMEDIATEオプションでは停止が失敗しました。
この状況の場合はABORTオプションでDBを強制終了します。
SQL> startup ORACLE instance started. Total System Global Area 801701888 bytes Fixed Size 2293496 bytes Variable Size 327155976 bytes Database Buffers 465567744 bytes Redo Buffers 6684672 bytes ORA-00205: error in identifying control file, check alert log for more info SQL> SELECT status FROM v$instance; STATUS ------------ STARTED
起動に失敗しました。制御ファイルはNOMOUNT時に読み込まれる為、読み込みに失敗するとNOMOUNT(STARTED)状態で停止します。
今回は制御ファイルを削除したので、どのファイルが破損しているかはわかっていますが、もし現場でこの状態となった場合、この情報だけではどのファイルが破損しているのかは不明確です。
この様な場合、アラートログを確認しましょう。
アラートログにはDBエラー詳細情報などが出力されています。
アラートログは「diagnostic_dest」パラメータで定義されているディレクトリの配下に作成されます。
SQL> show parameter diag
NAME TYPE VALUE
---------------------------- ----------- ------------------------------
diagnostic_dest string /u01/app/oracle
そのパラメータの配下にdiagディレクトリが作成され、さらにdiag配下は複数のディレクトリで構成されます。
$ cd /u01/app/oracle/diag $ ls afdboot asm clients diagtool em ios netcman plsqlapp tnslsnr apx asmtool crs dps gsm lsnrctl ofm rdbms
diagディレクトリ配下は各Oracleの機能などで分類されており、DBログはrdbmsディレクトリに格納されます。
参考ですが、DBログは以下のディレクトリに格納されます。
/u01/app/oracle/diag/rdbms/DB名/SID名/trace
$ tail -10 /u01/app/oracle/diag/rdbms/orcl/orcl/trace/alert_orcl.log
…
ORA-00210: cannot open the specified control file
ORA-00202: control file: '/u01/app/oracle/oradata/orcl/control03.ctl'
アラートログにはどのファイルが存在しないかが記載されています。
それでは復旧していきましょう。
復旧方法は破損していない制御ファイルをコピーするだけです。
$ cd /u01/app/oracle/oradata/orcl/ $ ls -l control*.ctl -rw-r-----. 1 oracle dba 18169856 3月 22 14:01 2016 control01.ctl -rw-r-----. 1 oracle dba 18169856 3月 22 14:01 2016 control02.ctl $ cp -p control01.ctl control03.ctl
これで復旧は終了です。それではDBを起動してみましょう。
$ sqlplus / as sysdba SQL> SELECT status FROM v$instance; STATUS ------------ STARTED SQL> ALTER DATABASE MOUNT; Database altered. SQL> ALTER DATABASE OPEN; Database altered.
上記が制御ファイルが一部破損したときの復旧方法です。制御ファイルが
全損してしまった場合、バックアップからの復旧となり、DBの停止時間も大幅に増えてしまいます。
このように復旧が簡単に済むので制御ファイルは多重化しましょう。
REDOログファイル破損時の復旧(一部)
REDOログのメンバーが1つだけ破損した時の動作、復旧を確認していきましょう。
SQL> select member,group# from v$logfile;
MEMBER GROUP# -------------------------------------------------- ---------- /u01/app/oracle/oradata/orcl/redo03.log 3 /u01/app/oracle/oradata/orcl/redo02.log 2 /u01/app/oracle/oradata/orcl/redo01.log 1 /u01/app/oracle/oradata/orcl/redo01_01.log 1 SQL> ! rm /u01/app/oracle/oradata/orcl/redo01_01.log SQL> ! ls -l /u01/app/oracle/oradata/orcl/redo01_01.log ls: cannot access /u01/app/oracle/oradata/orcl/redo01_01.log : そのようなファイルやディレクトリはありません
REDOログの1つのメンバーを削除したのでDB再起動してみます。
SQL> startup force ORACLE instance started. Total System Global Area 801701888 bytes Fixed Size 2293496 bytes Variable Size 327155976 bytes Database Buffers 465567744 bytes Redo Buffers 6684672 bytes Database mounted. Database opened. SQL> SELECT status FROM v$instance; STATUS ------------ OPEN
startup forceは起動中のDBを強制停止し再起動します。DBを再起動しましたが、起動は失敗せず、OPENまで起動しました。REDOログメンバー1つが破損しても、グループ内にメンバーが残っていれば、DBは停止しないからです。
それではアラートログを確認してみましょう。
Errors in file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/orcl_ora_6178.trc: ORA-00313: open failed for members of log group 1 of thread 1 ORA-00312: online log 1 thread 1:'/u01/app/oracle/oradata/orcl/redo01_01.log' ORA-27037: unable to obtain file status
アラートログにはどのファイルが破損しているのかが出力されています。
それでは復旧していきましょう。復旧方法は制御ファイルと同様です。
$ cd /u01/app/oracle/oradata/orcl/ $ ls redo0* redo01.log redo02.log redo03.log $ cp -p redo01.log redo01_01.log $ ls redo0* redo01.log redo01_01.log redo02.log redo03.log
REDOログの一部破損の場合、破損していないREDOログファイルをコピーするだけです。REDOログの全メンバーが破損した場合は、バックアップからの復旧となるので、
多重化を必ず行うようにしましょう。
以上がバックアップリカバリのご紹介となります。今回は制御ファイルとREDOログファイルの多重化と一部破損時の復旧方法について確認していきました。