Real Application Cluster(RAC)とは
RACの説明をする前に通常のデータベースのシングル構成について考えていきます。
データベースのシングル構成は以下のようにデータベースサーバが1つで、
インスタンスとデータベースは1対1という特徴があります。
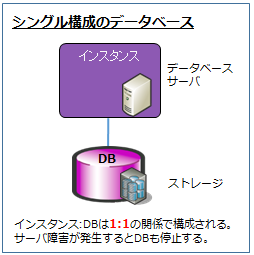
上記構成はサーバ障害が発生するとデータベースは停止してしまう為、
復旧するまでサービスを再開することができません。
24時間稼働し続けないといけないシステムではこの構成ではリスクが高いといえます。
そこでクラスタリングという機能を使用することでサーバ障害などが発生しても
サービスを継続することが可能です。
クラスタとは日本語訳では「房」という意味を持ちます。
ぶどうは房にたくさんの実を束ねているように、クラスタとは複数のサーバを束ねることにより、
1つのサーバが壊れてしまっても、別のサーバを使用することで、処理を継続させることが出来ます。
クラスタウェアとはその複数サーバを管理する為のソフトウェアです。
銀行のシステムを1つのデータベースサーバで運用しており、サーバの障害でDBがダウン
してしまったら、ATMから残高確認、預け入れ、引き出しが出来なくなってしまいます。
しかし、クラスタ構成にすることにより、サーバ障害時も即座に別のサーバを利用することにより、
停止時間の影響を少なくすることが出来ます。
Real Application Cluster(以下、RAC)はOracle社が提供するクラスタウェア構成であり、
共有ディスクを使用し、各DBサーバ(ノード)でインスタンスが稼動していることが特徴です。
その為、Real Application Clusterはサーバ障害時の可用性だけでなく、
同時に複数のサーバ(ノード)を利用することが出来るため、
DB性能も向上させることができます。
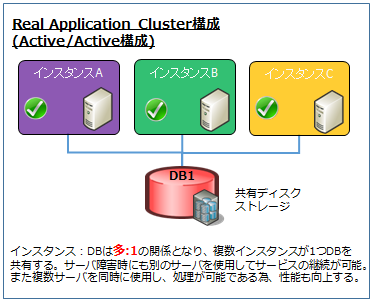
RAC構成の場合、上記の様に複数のサーバ上で複数のインスタンスを起動することで、
サーバ障害が発生した場合でも正常なインスタンスを使用して稼働することができます。
ただしRAC構成でもデータベースは1つであるため、メディア障害などはシングルポイントとなります。 データベースに対する可用性はRAIDやバックアップ等でカバーする必要があります。
Oracle社以外にもクラスタウェアを提供する会社はありますが、
現在のところすべてのサーバが稼動する構成はRAC構成以外にありません。
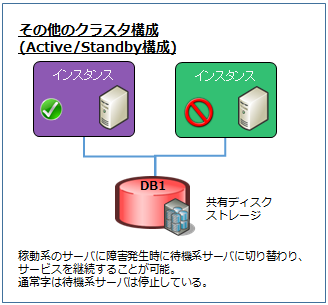
上記構成もクラスタ構成ですが稼動系、待機系サーバが存在し、稼動系サーバが障害時に
待機系サーバを起動することで、可用性を高める構成です。
通常時は待機系サーバは停止しているため、可用性は高めることは出来ますが、
DB性能を向上させることはできません。
クラスタウェアの役割
クラスタウェアはサーバの可用性を高めるソフトウェアです。
サーバに障害が発生したら別のサーバにリソースをフェイルオーバーし
サービスを継続させます。大きくは以下の役割を行います。
・リソースの監視
・サーバの死活監視
一般的なクラスタウェアの機能はリソースの監視、サーバ間の死活監視です。
これは以前紹介したActive/Standbay構成も同様です。RAC構成も簡単に言うと上記の機能を
持っています。ただしRAC構成はすべてのサーバがActiveである為、データの同時アクセスを
管理する機構も備わっています。これは後ほどご紹介します。
リソースの監視
クラスタウェアの機能としてリソースの監視があります。リソースとはクラスタウェアが監視
する対象をいいます。監視とはリソースが障害などにより停止していないか定期的にチェックし
もし障害でダウンしていた場合は自ノード(サーバ)で起動させたり、別ノードにフェイルオーバー
させます。
各リソースには監視の間隔などが決まっており、現在のRAC環境では監視間隔などの時間変更は行えません。
このリソースの監視、起動、停止はCRSプロセス(CRSエージェント)が行います。
またリソースの監視間隔の情報などはOCRファイルに格納されます。
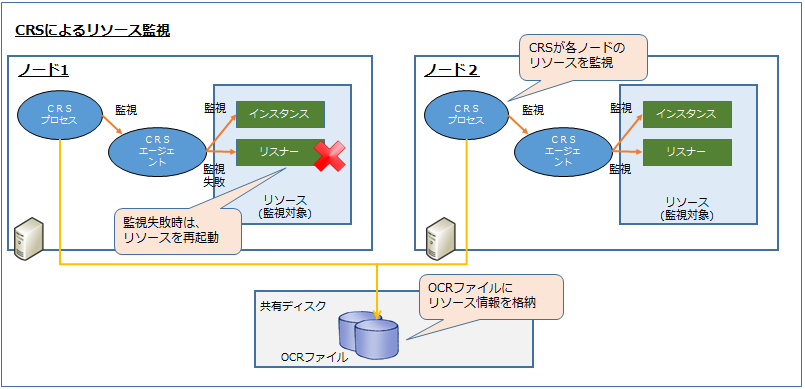
上記例ではノード1のリスナーが停止していたことを検知しています。
リスナーはその後、CRSによって再起動されます。
サーバの死活監視
サーバの死活監視はなぜ重要なのでしょうか。RACは全ノードがActiveである為、同時に同じデータに
アクセスする可能性があり、データ更新中にノード障害が発生し、そのデータを別ノードでも
更新しようとした場合、データ不整合が発生する可能性があります。
その為、サーバ障害が発生した場合、即座に検知し、そのノード上のデータに不整合が発生しないよう、
リカバリを実施します。
サーバの死活監視はCSSプロセスが行います。ノードで死活監視が1秒ごとに行われており、
サーバの生存確認を行っています。
この死活監視の処理ををハートビートと呼びます。ハートビートの結果は投票ディスクに
格納されます。CSSは重要な役割である為、CSSプロセス自身もCSSエージェントプロセス
により監視されています。
以下のようにCSSは各ノードに存在し、各ノードに対しハートビートを実施します。
ハートビートの結果は共有ディスクの投票ディスクに格納します。
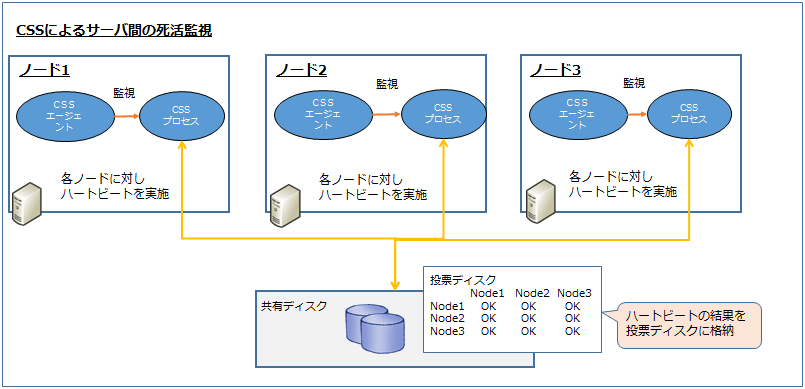
この為、データ不整合な状態を防ぐため、サーバ障害時には即座にサーバを切り離す処理を行います。
この障害により全ノードと通信が出来なくなる状態をスプリットブレインと呼びます。
サーバ障害が発生した場合の図が以下のとおりです。
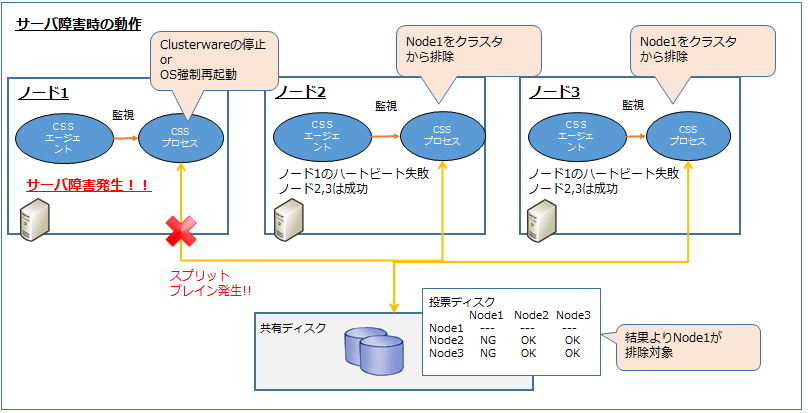
上記はノード1に障害が発生した場合の例です。CSSは各ノードに対し
ハートビートを行いますが、ノード1に対してはハートビートが失敗しています。
ハートビートの結果は投票ディスクに書かれますが、
その結果ノード1に障害発生していると判断し、ノード1の排除を行います。
排除はノード1のClusterwareの停止もしくはそれが出来ない場合は、
OSの強制再起動となります。
このようにスプリットブレインが発生した場合はをCSSというプロセスが
処理を行い、データ整合性を保とうとします。
クラスタウェアの役割は上記のような機能を担い、サーバの冗長化を実現することが出来ます。
DB障害などが発生しても、Oracleのクラスタウェアが障害の検知から再起動もしくは
フェイルオーバーを実施します。
Oracleクラスタウェアは正式名称グリッドインフラストラクチャ(GI)と呼びます。
いかがでしたでしょうか。本章ではクラスタウェアの基本的な役割についてご紹介していきました。
次章からはOracleクラスタウェアであるグリッドインフラストラクチャの動作について学んで行きたいと思います。